October 28, 2002
PythonCard 0.6.9
PythonCard is a GUI construction kit for building cross-platform desktop applications on Windows, Mac OS X, and Linux. The latest release of PythonCard includes over 30 sample applications and four tools to help users edit and build applications in Python.
The documentation page has links to installation instructions for Windows that covers installing Python, wxPython, and PythonCard. Check the changelog for a complete list of changes for release 0.6.9.
Posted by Andy Todd at 05:13 PM | Comments (0)
Changing Line Endings in VIM
I was somewhat vexed by this problem this afternoon for an hour or so. As a mental note to myself I thought I would put the solution here, then I am not going to forget it easily.
:set fileformat=unix<cr>
:w<cr>
I was trying to create a path file for the Cygwin installation of Python on my laptop. Except I created the file in Windows, and so when site.py tried to read the file it fell over the line endings. Of course I didn't realise this until I went through site.py line by line.
I then figured out that the file had windows line endings and so the script was balking at my perfectly reasonable suggestions for what to put into the sys.path environment variable.
Still, a valuable lesson was learned. In future, to make sure a configuration file for Cygwin is in the right format just open it in VIM and type the commands above. All is now well with the world.
The reminder was at the bottom of tip 26 on the VIM site. For the really curious, I was trying to automatically add a couple of directories to my sys.path every time I start up Python using the site customising hook.
Posted by Andy Todd at 03:37 PM | Comments (0)
October 23, 2002
Valid RSS
I joined in the fun started my Mark Pilgrim and Sam Ruby and validated my RSS 1.0 and RSS 2.0 feeds. After a little light template adjustment they now validate. All I have to do now is make my choice of a graphic to put here to prove it.
I must admit that I'm not a big fan of syndicated feeds. I prefer to view content in situ, rather than in a small text window. But thats just me, and in the spirit of accessibility if anyone wants to read this rambling tome in anything other than a browser then it is incumbent on me to make their lives as easy as possible.
Posted by Andy Todd at 09:52 AM | Comments (0)
October 16, 2002
Oracle 8.1.7 on Windows2000 with a Pentium 4
There is a snappy title if ever I read one. This entry is for you if you have had problems installing Oracle 8.1.7 (and above) on a Windows machine which happens to have a Pentium 4 processor.
I've just started a new job and they presented me with a spanking new laptop. As the resident Oracle guru I thought it incumbent on me to get a database up and running as soon as possible.
So I got the company copy of the Oracle8.1.7 database for Windows CD from the locked box and stuck it in the CD-Rom drive. Nothing. Nada. Zero. Zip. Zilch. Actually, that is not entirely true. The splash screen appeared, but when I selected "Install/De-install Oracle products" nothing happened.
After two days of head scratching, searching archaic forums (and the web) I have the answer to our problem. The java run time supplied with Oracle 8.1.7.0 (and up to 8.1.7.4) doesn't work on Windows running on a Pentium 4. Its all documented at Metalink, Oracle's support web site. If you have an account check out article number 131299.1
For those that haven't registered yet, copy the installation CD to a staging area. Rename any files you find there called symcjit.dll to symcjit.old. Then run setup.exe from the staging area and Bob is your Auntie's live in lover.
Except. A standard installation also puts a copy of Apache , complete with the JServ module in the Oracle installation. Unfortunately, the version of the JRE shipped with this software has the same problem. This is also documented on Metalink as document id 235547.999. This problem manifests as pop up messages when you start the OracleHTTP service saying things like "java.exe has failed" To resolve this problem download JRE 1.2.2_007 from http://java.sun.com/products/archive/j2se/1.2.2_007/jre/. Then you have a choice. You can simply install it to $ORACLE_HOME\Apache\jdk\jre, or you can install it to a staging area and copy the files jvm.dll and symcjit.dll from the staging area to the jre directory.
What a lovely way to spend a couple of days. Still, I can now query the scott/tiger tables.
Posted by Andy Todd at 04:30 PM | Comments (18)
October 09, 2002
Accessibility?
Its not a crusade or anything, but I am not a big fan of bad customer service. On the web this usually comes in the form of badly written web sites that have only been tested in IE. Well step forward today's contender, from the lovely folks at;
They have committed a number of venal sins. The site does not render properly in any of the browsers I am running under Debian but just about clearly enough that I can navigate through to the quotations page. Sadly I can do nothing whilst I am there. They have then failed even to say "this pages only works with xxx browsers" So, I thought I would give them a call to get a motor insurance quote. It only tooks me about ten minutes, and three levels deep in their site structure, to actually find a telephone number to call. Do they not want my business? Sheesh.
Posted by Andy Todd at 03:30 PM | Comments (0)
October 06, 2002
All things come to he who waits
On the 9th of January I was bemoaning how hard it is to set up a sources.list file under Debian. Well, I was just browsing some documentation and bugger me if I didn't come across netselect.
In a nutshell it automates the creation and maintenance of your /etc/apt/sources.list file, by pinging available mirrors and selecting the fastest one, then it writes the sources.list file for you. I'm off to install it now.
Posted by Andy Todd at 04:47 PM | Comments (0)
October 05, 2002
Not today sonny
After months in the wilderness I finally have decent connectivity again. Great. Especially as near the top of my to do list is to figure out how to install wxPython and PythonCard under Debian GNU/Linux and then document it on the project Wiki.
Now ppp dialup is a little tricker under Linux than Windows (one of the myriad of reasons why Linux still isn't ready for the mainstream) and you need a little more information than just a phone number and your username and password.
Specifically (to the best of my knowledge) you need to tell your machine how to resolve domain names. This is done using a nameserver which is supplied by your ISP. Under Windows this all happens automatically and you don't need to be any the wiser.
Linux, being a little bit more hardcore requires you to fiddle about with a couple of configuration files. For those who thirst for knowledge, I'm using WvDial possibly the simplest way of getting a Linux box to connect to a dial up ISP. With this you need to fiddle with two files; you need to specify the phone number, your username and your password in /etc/wvdial.conf and you need to put DNS information in /etc/resolv.conf. The first is easy, the second can be a little tricky without the right information.
Sadly, my ISP doesn't want me to know this much information, so I'm stuck with Windows for now.
Update
19:03 - A little light lift music later and the technical support desk at Vulture Capitalist came through with the goods. If you want to connect to their service try the following in your /etc/resolv.conf file;
domain vcisp.net
nameserver 212.159.11.155
nameserver 212.159.13.155
Posted by Andy Todd at 06:41 PM | Comments (0)
October 03, 2002
A little light munging
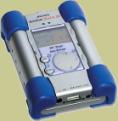 I love my new Archos Jukebox. But it was only after putting about a hundred CDs worth of music on it that I found a drawback.
I love my new Archos Jukebox. But it was only after putting about a hundred CDs worth of music on it that I found a drawback.
By default Musicmatch Jukebox, the MP3 writing software supplied with the unit, arranges tracks in a directory per album, and with albums grouped in directories by artist. The file name of each individual track is then simply the track title. Simple, really. When you play these tracks in Musicmatch jukebox you can select them in track order but when you play them on your Archos jukebox the tracks are played in alphabetical filename order. Which is fine, but does ruin the enjoyment of a quality concept album like Misplaced Childhood.
Rather than change the settings in Musicmatch and then re-record all one hundred plus CDs I decided on a radical plan. I would prepend the track number to the beginning of each filename on my Jukebox. So instead of "Lavender.mp3" the file would be called "03_Lavender.mp3". A task of mere minutes I thought, because I have Python at my command. In the end it was quite a simple task, but the process of writing that simple solution was a bit of a voyage of discovery which I thought I would share. Luckily for our purposes each MP3 file has some meta data encoded in it by the burning software. Looking at chapter three of Dive into Python there is an example of how to read the ID3v1.0 style tags in your MP3 files. After borrowing this code I realised the flaw in my cunning plan, there is no track number in the ID3v1.0 tag. A little investigation (at id3.org determined that I should be looking at the ID3v2.0 tag in my files.
Sure enough, with a little experimentation and minimal cursing I found out how to get the relevant parts of the ID3 tag, namely the track title and track number. Its as simple as;
def getTagData(directoryName, fileName):
"Return track number and title from ID3v2 tag of fileName"
file = open(os.path.join(directoryName, fileName))
tagHeader = file.read(1024) # If its a large header this won't be enough
file.close()
# Get the track number
numberPosition = tagHeader.find("TRCK")
if numberPosition:
start = numberPosition + 11
end = numberPosition + 13
trackNo = tagHeader[start:end]
if trackNo[1] == "T":
trackNo = trackNo[0]
try:
trackNumber = int(trackNo)
except:
trackNumber = 0 # Nice default
# Get the track title to a maximum of 256 characters
filenamePosition = tagHeader.find("TIT2")
if filenamePosition:
start = filenamePosition + 10
startLength = filenamePosition + 4
endLength = filenamePosition + 8
length = struct.unpack('bbbb', tagHeader[startLength:endLength])
end = start + length[3] # Only need other components if file name is more than 256 characters
trackName = tagHeader[start:end].replace("\00", " ").strip()
# All done, return to our calling function
return trackNumber, trackName
Easy really. All you really need to know is that ID3v2.0 allows you to put as many (or as few) tags within your tag (what they call frames). Each frame is identified by a name, the two we are interested in here are "TRCK" for track number and "TIT2" for track name. Rather than fiendishly slice up the up the entire tag I just asssume these frames are in the first 1024 bytes of the track and then search for those strings. What immediately follows the frame identified varys from frame to frame, but you should be able to infer the details of the two frames we are interested in from the preceding code. If not, have a look at the website.
Having mastered the ability to read the tags and garner the information needed to rename each file I had to perform the change. In Python, this is a cinch;
def rename(directoryName, fileName):
trackNumber, trackName = getTagData(directoryName, fileName)
if trackNumber == 0:
return # We haven't picked up the tag information
if trackNumber < 10:
prefix = '0'+str(trackNumber)
else:
prefix = str(trackNumber)
modifiedFileName = prefix + '_' + trackName + '.mp3'
if modifiedFileName != fileName:
print "New : %s\nOld : %s" % ( modifiedFileName, fileName )
os.rename(os.path.join(directoryName, fileName), os.path.join(directoryName, modifiedFileName))
With these two building blocks its a simple matter to go through my entire MP3 collection, well almost. First we have to find them all. If you remember from the top of this piece my collection is organised into a hierarchy of directories.
The Python library comes to our aid here. The os.path module has a function called walk which, given a starting point and a function, calls the function for every directory it finds under the starting point. So the last part of my script is to write a function that should be called for every directory in my MP3 collection. Something like;
def processDir(arg, dirname, names):
for file in names:
if os.path.splitext(file)[1] in arg:
rename(dirname, file)
You can see that I've employed the optional third argument to a function called from os.path.walk, a list of arguments which in this case are file extensions so that we only rename MP3 files. This is then called as follows;
if __name__ == "__main__":
os.path.walk(songDirectory, processDir, [".mp3"])
Done. Now, why did I post this here? Well, this is the most useful code I've written in a while and I thought it might be of interest to document my development process. Not least because someone might stumble across this humble weblog and tell me how to do it better, or more efficiently, or even more object-oriented-ly.
Of course, a little success has got me thinking. My next personal project will be a random play list generator. I've already got a first cut of pseudo-code;
class archosPlaylist:
def __init__(self, length=20):
self.trackCount = length
self.tracks = []
def getTracks(self);
for index in range(self.trackCount)
# select a song
# add it to the playlist
def showTracks(self):
for track in self.tracks[]
print track.name
def write(self, filename):
# output self.tracks to filename
Now all I have to do is write the program.
Posted by Andy Todd at 04:15 PM | Comments (1)